Works with your existing data sources
 Dynamics 365 CE
Dynamics 365 CE Dataverse
Dataverse SQL Server
SQL Server PostgreSQL
PostgreSQL MySQL
MySQL MariaDB
MariaDB Oracle
OracleDuplicate records quietly undermine your CRM, reporting, and operations. DeDuplica detects, reviews, and resolves them — across your enterprise databases, at scale, with matching rules you control.
Works with your existing data sources
Dynamics 365 CE
Dataverse
SQL Server
PostgreSQL
MySQL
MariaDB
OracleIn large organisations, data accumulates across systems, migrations, and integrations. Over time, duplicates erode the single source of truth you need to operate with confidence.
Sales teams working with multiple versions of the same customer — different addresses, different history, different owners.
Aggregated metrics built on duplicated data produce figures that senior leadership can no longer rely on.
Every system-to-system sync is an opportunity to duplicate further. Without deduplication in the loop, the problem compounds.
Spreadsheet-based deduplication projects take months, go stale immediately, and can’t scale to enterprise volumes.
DeDuplica is designed to get you from simple configuration to clean data quickly, without requiring specialised data engineering resources.
Add a connection to any supported system — Microsoft Dynamics 365, Dataverse, SQL Server, PostgreSQL, MySQL, MariaDB, or Oracle. Credentials are stored securely and never leave your configured environment.
Create a Job targeting a specific table. Select the fields to compare and choose a matching algorithm per field — exact match, fuzzy text similarity, phonetic matching, or nickname resolution. Combine multiple fields to model your exact business definition of a duplicate.
Found duplicates are logged for review. Where supported (Dynamics, Dataverse), records can be auto-merged according to field-level merge rules you define. For other sources, webhook callbacks let you process results programmatically. Schedule runs to keep data clean continuously.
DeDuplica goes beyond simple exact-match detection. It is built to handle the ambiguity and inconsistency of enterprise data at scale.
Detect duplicates even when spellings differ, names are abbreviated, or data was entered inconsistently across systems.
Combine multiple fields — name, address, phone, email — each with its own algorithm and weight, to precisely reflect your business logic.
Define per-field merge strategies: keep master, keep most recent, keep longest, or custom priority rules. DeDuplica pre-builds the merged JSON for you.
When automatic merge isn’t available, trigger webhooks with full duplicate context so your existing workflows or ETL processes can take action.
Configure jobs to run on a schedule so your data stays clean on an ongoing basis — not just after a one-off clean-up project.
Enterprise plan supports deploying a local agent inside your own infrastructure. Your data never leaves your network — DeDuplica orchestrates; you retain full control.
Mark a pair of records as “not duplicates” and the system remembers. Stop being notified about false positives you’ve already reviewed.
Connect to Dynamics 365, Dataverse, SQL Server, PostgreSQL, MySQL, MariaDB, and Oracle. One platform, all your enterprise databases.
Every run produces a structured log of found duplicates, actions taken, and merge outputs — keeping your team informed and audits straightforward.
DeDuplica is a dedicated deduplication platform with a clear, focused interface designed for administrators, data stewards, and integration teams.
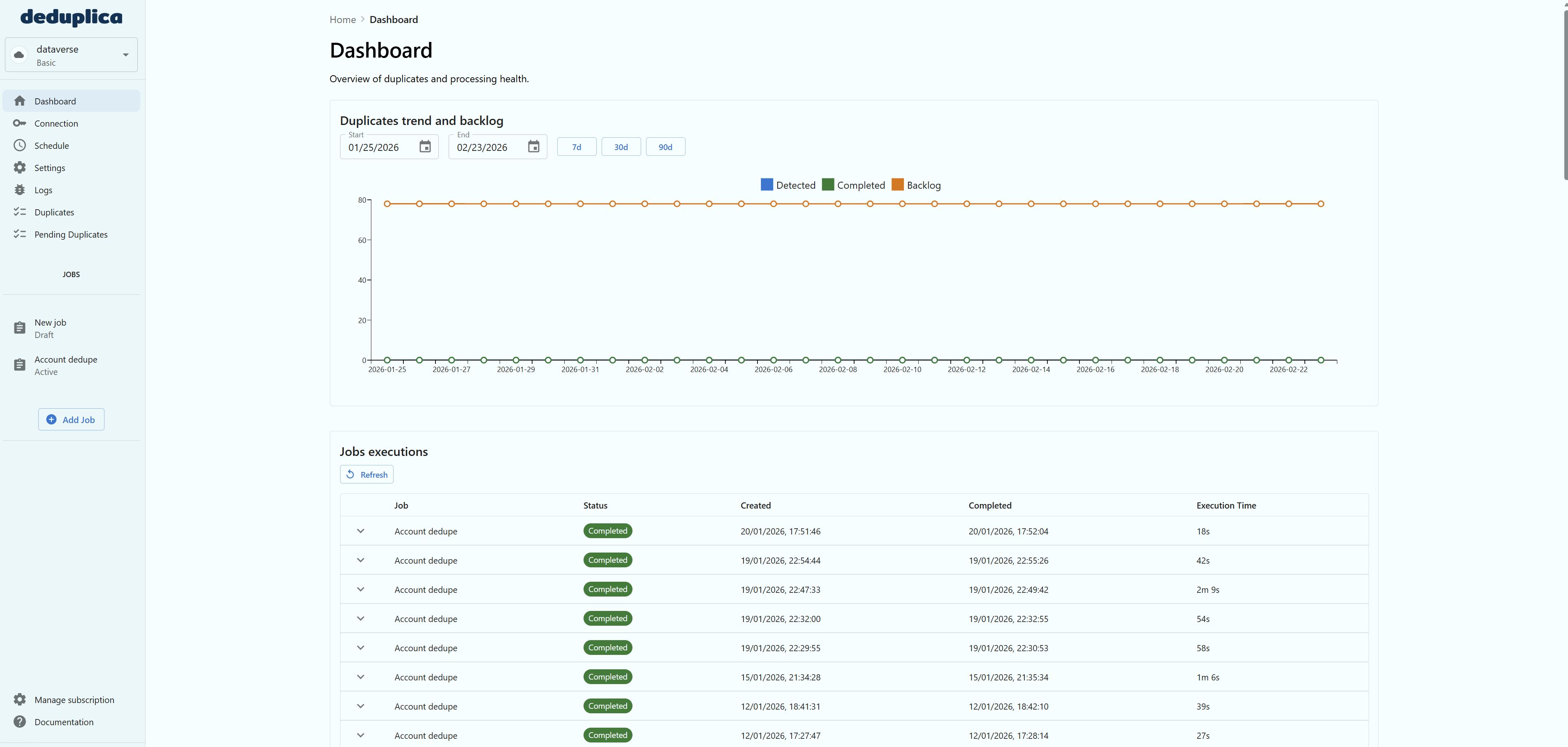
No credit card required to start. Upgrade as your data volumes grow.
Evaluate DeDuplica and get started with smaller datasets at no cost.
For growing teams running regular deduplication on production data.
For organisations with large datasets and complex deduplication workflows.
For enterprise-scale workloads with compliance requirements.
The team behind DeDuplica has deep expertise in enterprise data deduplication and integration. If your scenario goes beyond standard configuration — complex merge logic, multi-system orchestration, bespoke processing pipelines — we can work with you directly.
Talk to an ExpertJoin organisations already using DeDuplica to maintain a single, reliable view of their enterprise data. Start free — no commitment required.
Questions before you start? Get in touch





